
대규모 데이터를 처리하는 게시판 시리즈
(1) - 웹애플리케이션 개발 및 더미데이터 생성
(2) - JMeter와 테스트플랜 생성, 최초 성능 테스트
(3) - Index(1)
(4) - Index(2)
(4) - DB Connection
(5) - InnoDB Buffer Pool
(6) - Replication, Partitioning성능 개선 지점 : Connection Pool
Resource Pooling
Resource Pooling이란 자원의 생성과 삭제에 컴퓨팅 자원이 많이 소모되며 이 작업이 빈번하게 발생되는 경우 미리 지정된 개수의 자원을 만들어 놓고 사용자 측에서 이를 빌려가서 사용한 뒤 반납하게 만들어 불필요한 오버헤드를 줄이는 기법입니다.
서버 프로그램에서는 매 작업마다 클라이언트의 요청을 처리하는 쓰레드를 생성하고 해제하는 것은 오버헤드가 크기 때문에, 미리 여러 쓰레드를 생성하고 큐에서 대기 중인 작업을 수행하게 만들어 재사용을 합니다.
 https://sihyung92.oopy.io/spring/1
https://sihyung92.oopy.io/spring/1
또한 DB와 연결되어서 정보를 주고 받아야 하는 프로그램은 매 DB 요청마다 Connection을 생성하지 않고, 프로그램 초기화 시 미리 Connection을 연결해놓고 이를 사용하곤 합니다.
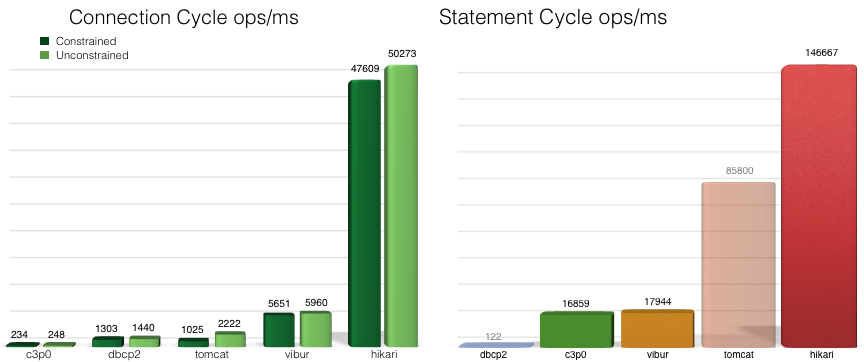
DBCP와 성능 trade-off
Database Connection Pool (DBCP)의 커넥션 개수는 애플리케이션 서버와 DB 서버에 여러 영향을 미칩니다.
만약 데이터베이스 커넥션의 개수가 적다면 애플리케이션 서버는 초기 구동이 빨라지고 더 많은 유휴 메모리 공간을 가질 수 있습니다. 반면 적은 수의 커넥션은 클라이언트의 요청을 충분히 처리하기에는 부족할 수 있고, 이 경우 여러 쓰레드들이 커넥션을 획득하기 위해 기다리는 병목현상이 발생할 수 있습니다.
한편 DB 서버에 입장에서 Connection이 적다는 것은 동시에 처리해야할 일들이 적다는 것을 의미합니다. 따라서 각 요청들은 DB 서버에서 충분한 연산 시간을 확보할 수 있어 빠르게 응답을 받을 수 있습니다. 하지만 이 과정에서 Disk I/O 등이 발생한다면 CPU가 idle해지고 cpu usage가 줄어드는 현상이 발생할 것입니다.
만약 데이터베이스 커넥션의 개수가 많다면, 애플리케이션 서버는 초기에 더 많은 커넥션을 생성하기 위해서 시간을 더 많이 쓸 것이고 그만큼의 메모리를 더 사용할 것입니다. 대신 전에 발생했던 쓰레드들이 커넥션을 획득하기 위해 기다리는 현상은 덜 발생할 것이며, 쓰레드들은 기존보다 여유있게 커넥션을 획득할 것입니다. 하지만 이것이 병목현상을 제거한다고 할 수는 없는데, 그 이유는 DB 서버에서 기인합니다.
DB 서버 입장에서 Connection이 많다는 것은 그만큼 많은 일들을 동시에 처리해야함을 의미합니다. 따라서 DB 서버는 여러 요청을 동시에 처리하기 위해 지속적으로 Context Switch를 수행할 것이며, 이 과정에서 각각의 요청은 기존만큼 연산시간을 확보하지 못하고 wait 상태로 기다리게 됩니다. 따라서 각각의 요청들의 응답시간은 기존보다 길어질 것이며, 이는 애플리케이션 서버에 또 다른 형태의 병목현상을 낳게 됩니다.
Connection Pool의 개수는 어떻게 설정해야하는가?
 https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing그렇다면 DB Connection Pool의 개수는 어떻게 결정해야할까요? 물론 애플리케이션 서버와 DB 서버의 스펙, 요청의 특징과 분포, 부하의 정도에 따라서 다 다를 것이지만, 흔히 일반적으로 권장되는 개수 선정 방법이 있습니다.
만약 DB 서버에 8개의 컴퓨팅 코어가 존재한다면, 8개의 커넥션 개수를 유지했을 때 최적의 성능을 제공할 수 있으며, 그 이상의 커넥션이 생성된다면 context switch의 오버헤드로 인해 처리량이 줄어들게 됩니다. 하지만 이는 Disk I/O 와 네트워크 비용을 무시한 결론입니다. Disk I/O를 기다리는 시간과 네트워크 버퍼가 가득차서 정지되는 상황에서는 CPU가 idle 해지기 때문에, 컴퓨팅 코어의 개수보다는 많은 커넥션을 만들어야 DB 서버를 효율적으로 사용할 수 있을 것입니다.
HicariCP의 문서에서는 다음과 같은 공식을 통해 초기 개수를 설정하고 이 값을 중심으로 다양한 풀 개수를 테스트해볼 것을 권장하고 있습니다.
과거 HDD를 사용할 때에 disk를 읽기 위해서는 disk의 spindle을 회전시키고 데이터를 읽어와야 했습니다. 이 과정은 물리적인 회전을 포함하므로 하나의 disk에서 동시에 수행될 수 있는 I/O 요청의 개수는 하나로 제한 됩니다. 따라서 이 경우 effective_spindle_count는 하드 디스크의 개수와 동일합니다.
하지만 SSD를 사용하는 환경에서는 병렬 I/O 요청이 가능하므로, 공식에 대해서는 기존과 다른 해석을 해야합니다.

해당 글에서는 SSD에서 데이터를 읽는 경우 풀 크기를 코어 수와 동일하게 맞추라고 권장하고 있습니다. 또한 다른 글에서는 core_count * 2 부터 시작해서 올려가며 최적의 수를 파악하라는 글도 보았습니다. RDS의 프리티어 db.t3.micro는 2개의 가상 CPU를 제공하므로 core_count는 2이므로, 2부터 시작해서 커넥션 풀의 개수를 올려가며 어떤 개수에서 애플리케이션의 throughput이 가장 높은지 확인해보겠습니다.
새로운 테스트 방법
지금까지는 고정된 개수의 요청 전체를 처리하는데에 몇초가 걸리는지를 바탕으로 성능을 평가했습니다. 하지만 이러한 구조로는 각각의 요청 별 응답 시간에 대한 고려를 하기에 어렵습니다. DB Connection Pool의 변경은 throughput은 증가시키면서 개별 응답시간을 낮출 가능성을 가지고 있습니다. 따라서 새로운 테스트 방식을 고안하기로 했습니다.
성능 테스트의 종류
- Load Test : 사전에 결정된 피크 트래픽 시점의 부하 상황에서의 시스템 성능을 검증합니다.
- Stress Test : 피크 트래픽보다 더 높은 부하 상황에서 시스템이 장애를 적절히 대처하는지, 이후 부하가 정상적으로 돌아갈 때 우아하게 복구되는지 검증합니다.
- Endurance Test : 장기간에 걸쳐 나타나는 메모리 누수와 같은 문제들을 찾아내기 위해 8시간 이상의 기간에 걸쳐 시스템의 안정성을 검증합니다.
- Spike Test : 갑작스러운 사용량 급증이 발생했을 때의 시스템 성능을 검증합니다.
- Breakpoint Test : 사용자의 요청의 수를 점진적으로 증가시켜서, 시스템의 장애 지점을 확인합니다.
어떻게 테스트할 것인가
DB Connection Pool의 개수 변경에 대해 체계적으로 테스트하기 위해 다음과 같은 방식을 따릅니다.
- Load Test를 수행하되, 기존에는 요청의 개수를 결정했다면 이후 테스트에서는 사용자의 수를 결정합니다.
- 요청 분류 별로 사용자 수를 지정하고, 각각의 사용자는 응답이 온 뒤 바로 새로운 요청을 보내게 합니다.
- 이 상황을 60초간 지속시킵니다.
이러한 테스트 방식을 수행하기 위해서는 JMeter 플러그인 ‘Custom Thread Group’을 사용할 수 있습니다.
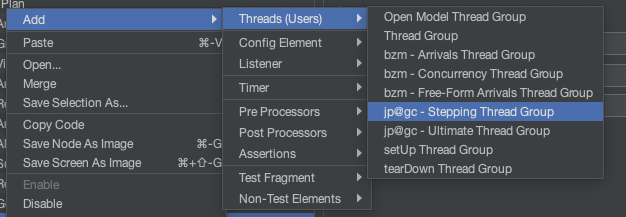
Custom Thread Group 플러그인을 설치하면 Stepping Thread Group과 Ultimate Thread Group을 사용할 수 있습니다.
Stepping Thread Group은 Break-point test를 하기에 적합한 쓰레드 그룹으로, 쓰레드의 수를 점진적으로 증가시키는 기능을 가지고 있습니다.
Ultimate Thread Group은 조금 더 유연하게 시나리오를 구성할 수 있는 쓰레드 그룹으로, 쓰레드를 조절하는 각각의 스케줄을 기반으로 부하를 높였다가 낮추는 패턴과 같이 더욱 복잡한 상황을 만들어 내기에 적합합니다.
테스트 계획에는 복잡한 시나리오가 필요하지 않으므로 Stepping Thread Group을 사용하려 했지만 쓰레드 종료 시점에 graceful하게 종료되지 못하는 이슈가 발생하여 Ultimate Thread Group을 사용했습니다. 다음과 같이 쓰레드 그룹을 작성해놓으면 첫 10초간 80개의 사용자를 점진적으로 생성한 뒤 60초간 유지하고 15초에 걸쳐서 쓰레드를 종료시킵니다.
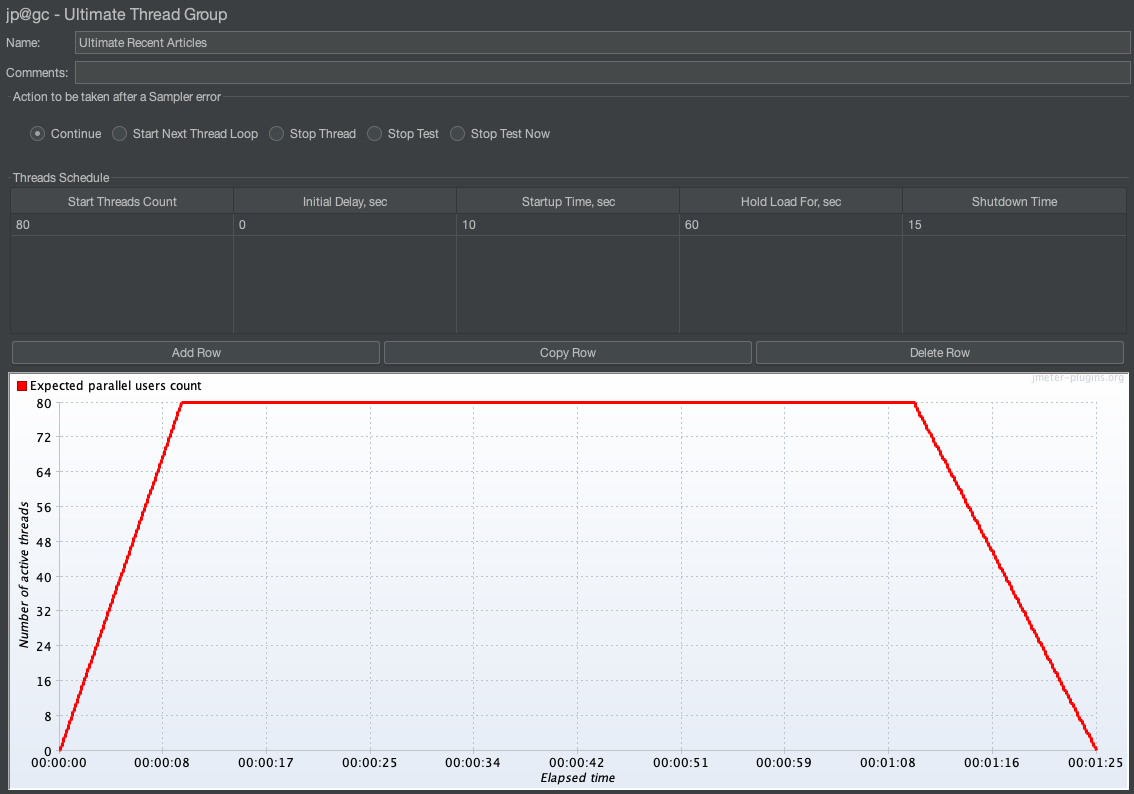

테스트가 종료되면 다음과 같은 결과를 확인할 수 있습니다.

테스트 수행
Connection Pool 개수 설정하는 법
application.yml에 다음과 같이 작성하여 커넥션 풀 개수를 설정할 수 있습니다.
spring:
datasource:
hikari:
maximum-pool-size: {커넥션 풀 개수}
커넥션 풀 개수에 2를 넣고 프로그램을 동작시키면 RDS 콘솔에서 DB에 연결된 커넥션 수가 2개임을 확인할 수 있습니다.

테스트 결과
테스트 결과는 다음과 같습니다. 표가 많은 관계로 토글을 통해 확인할 수 있게 넣어놨으며, 쉬운 분석을 위해 별도의 통계 그래프를 작성하였습니다.
결과 통계
Connection의 개수가 2개일 때

Connection 2, User 120 
Connection 2, User 240 Connection의 개수가 4개일 때

Connection 4, User 120 
Connection 4, User 240 Connection의 개수가 8개일 때

Connection 8, User 120 
Connection 8, User 240 Connection의 개수가 16개일 때

Connection 16, User 120 
Conenction 16, User 240 Connection의 개수가 24개일 때

Connection 24, User 120 
Connection 24, User 240 Connection의 개수가 48개일 때

Connection 48, User 120 
Connection 48, User 240
왼쪽 그래프는 사용자가 120명일 때와 240명일 때의 TPS를 표현한 그래프입니다. 사용자 수가 120명인 경우 TPS는 Connection의 개수가 증가함에 따라 함께 증가하는 경향을 보였고, 사용자 수가 240명인 경우 TPS는 Connection 개수가 8개일 때 최고값을 찍고 점차 줄어드는 경향을 보였습니다.
오른쪽 그래프는 response time을 사용자 수와 백분위 수로 구분하여 표현한 그래프입니다. Connection의 개수가 적은 경우 95th와 99th는 거의 차이가 나지 않았지만, Connection 개수가 늘어날수록 차이가 커지는 경향을 보여줍니다. 사용자 수가 120명인 경우 95th 응답 시간은 대체로 비슷했으나 Connection이 48개인 경우에서 크게 늘어났고, 사용자 수가 240명인 경우 응답시간은 Connection이 8개까지 늘어남에 따라 점차 감소했으며 이후 다시 증가했습니다.

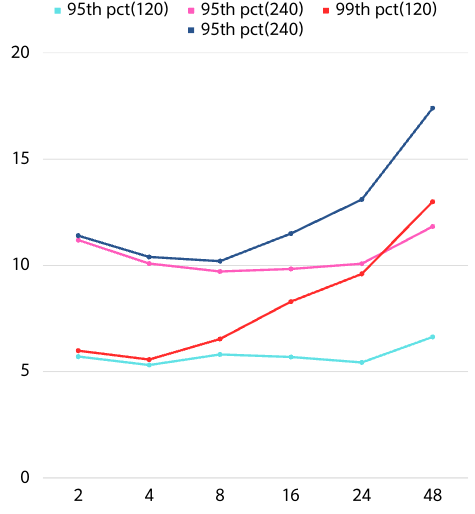
Connection Pool 개수 결정
Connection Pool의 개수는 피크 타임의 부하의 크기, 목표로 하는 TPS와 response time 등에 의해 적절히 선택해야 합니다.
예를 들어 피크 타임에 부하가 크지 않아 약 120명의 사용자가 접근할 것으로 예상된다면, 다음과 같은 선택지 중 하나를 고를 수 있을 것입니다.
95%에 해당하는 대부분의 요청의 응답시간은 커넥션의 개수가 2개일 때부터 24개일 때까지 거기서 거기이니, TPS를 올리기 위해 16~24개 중의 값을 선택해야겠어
TPS를 조금 포기하더라도, 일부 요청이 응답 시간이 튀는 현상이 발생하면 고객 경험에 있어서 안좋은 효과가 날테니 요청들이 안정적으로 처리될 수 있는 4개에서 8개 사이의 값을 선택해야겠어
만약 피크 타임에 부하가 커서 약 240명의 사용자가 접근할 것으로 예상된다면, 다음과 같은 선택을 할 수 있을 것입니다.
connection이 8개인 경우 TPS도 높고 개별 응답시간도 짧으니 8개로 설정해야겠어
실질적인 의사결정은 여기서 고려되지 않은 피크 타임의 지속도, 시스템 자원 사용량, 트래픽의 패턴 등을 추가로 고려해야할 것입니다. 이 예제에서는 비교적 높은 트래픽에서 좋은 성능을 보인 8개로 결정하고 이후 개선지점들을 알아보겠습니다.
Uploaded by N2T
