
대규모 데이터를 처리하는 게시판 시리즈
(1) - 웹애플리케이션 개발 및 더미데이터 생성
(2) - JMeter와 테스트플랜 생성, 최초 성능 테스트
(3) - Index(1)
(4) - Index(2)
(4) - DB Connection
(5) - InnoDB Buffer Pool
(6) - Replication, Partitioning성능 개선 지점 : DB와 쿼리
암달의 법칙
암달의 법칙을 통해 시스템에서 우선적으로 개선해야하는 부분을 판단할 수 있습니다. 현재 서버로 들어오는 요청들은 대부분의 시간을 DB Connection을 획득하기 위해 기다리는데에 사용하고 있습니다. 심지어 몇몇 요청들은 DB Connection을 30초 이상 획득하지 못하여 에러를 반환하고 있습니다.
이러한 상황이 발생한 근본적인 원인은 쿼리의 수행속도가 늦어 먼저 DB Connection을 획득한 요청들이 금방 반환해주지 못하고 있기 때문입니다. 따라서 시스템을 개선하기 위해서는 DB 쿼리를 최적화해야 할 것입니다.

결국 우리는 이를 통해 시스템에서 가장 큰 시간을 차지하고 있는 서브 태스크를 우선적으로 개선해야 전체 시스템의 성능을 효과적으로 높일 수 있음을 알 수 있습니다.
Index

Index는 데이터의 빠른 조회를 위해 레코드의 키와 주소 쌍을 정렬하여 별도의 저장공간에 저장해 놓은 자료구조입니다.
별도의 저장공간을 차지해야하며, 테이블 데이터의 변동에 따라 동적으로 수정되어야 하기 때문에 삽입, 수정, 삭제에 있어서 추가적인 처리가 이뤄져야 합니다. 이렇게 일부 저장공간과 작업속도를 희생함을 통해 조회의 속도를 끌어올릴 수 있습니다. 일반적인 웹앱의 DB 서버에서는 대부분의 작업이 읽기에 치중되어있기 때문에 인덱스를 사용하는 것은 효과적인 방안이 될 수 있습니다.
Optimizer와 힌트
MySQL Engine은 여러 구성요소가 있는데, 그 중 Optimizer은 분석된 SQL을 통해 어떻게 데이터를 효율적으로 처리할 수 있는지 결정하는 역할을 합니다. Optimizer은 불필요한 조건을 제거하고 복잡한 연산을 단순화하며, 테이블 조인이 발생할 때 어떤 순서로 테이블을 읽을지, 어떠한 인덱스를 사용할지, 어떻게 테이블을 가공할 지 등을 결정합니다.
Optimizer가 결정한 처리 방식은 실행 계획이라고 부릅니다. 실행 계획은 explain 이라는 키워드를 통해 쿼리로 질의하여 확인할 수 있습니다.
explain
select *
from article a1_0
order by a1_0.id desc
limit 491980,10;
하지만 Optimizer가 항상 최적의 선택을 하는 것은 아닙니다. 이 경우 개발자는 쿼리를 수행시킬 때 Optimizer에게 힌트를 제공하여, Optimizer가 스스로 결정하지 않고 쿼리에서 주어진 처리 방식을 채택하게 할 수 있습니다.
SELECT /*+ NO_RANGE_OPTIMIZATION(t3 PRIMARY, f2_idx) */ f1
FROM t3 WHERE f1 > 30 AND f1 < 33;
SELECT /*+ BKA(t1) NO_BKA(t2) */ * FROM t1 INNER JOIN t2 WHERE ...;
SELECT /*+ NO_ICP(t1, t2) */ * FROM t1 INNER JOIN t2 WHERE ...;
SELECT /*+ SEMIJOIN(FIRSTMATCH, LOOSESCAN) */ * FROM t1 ...;
EXPLAIN SELECT /*+ NO_ICP(t1) */ * FROM t1 WHERE ...;
SELECT /*+ MERGE(dt) */ * FROM (SELECT * FROM t1) AS dt;
INSERT /*+ SET_VAR(foreign_key_checks=OFF) */ INTO t2 VALUES(2);슬로우 쿼리 확인
DB 쿼리에서의 병목지점을 찾기 위해서는 수행시간이 긴 쿼리를 찾아야 합니다. 이를 찾기 위해서 MySQL이 제공하는 기능을 빌려 분석해보겠습니다.
MySQL은 슬로우 쿼리 로그 기능을 제공합니다. 다음은 슬로우 쿼리와 관련된 시스템 변수들입니다.
slow_query_log: 1인 경우 로그를 생성하며, 0인 경우 로깅을 하지 않습니다.
long_query_time(default: 10) : 이 값을 기준으로 이보다 더 긴 시간이 걸린 쿼리들을 슬로우 쿼리로 지정하고 로깅을 합니다.
slow_query_log_file: 슬로우 쿼리 로깅 파일의 위치를 지정합니다.
log_output: 로그를 테이블에 저장할지 파일에 저장할지 결정할 수 있습니다.
RDS 설정
위에서 설명한 속성들을 변경하여 RDS 인스턴스에 적용하기 위해서는 파라미터 그룹의 변수를 수정해주어야 합니다.
RDS에 들어가 왼쪽 탭에서 파라미터 그룹을 통해 이 RDS에서 사용할 파라미터 그룹을 만들고 값들을 수정해주었습니다.

long_query_time은 0으로 설정하여 발생하는 모든 쿼리를 확인할 수 있게 하였고, log_output은 table로 하여 RDS 콘솔에서 번거롭게 로그를 확인하지 않고 테이블 조회를 통해 로그를 확인할 수 있게 했습니다.
이후 파라미터 그룹을 RDS 인스턴스에 적용시키고 재부팅 한 뒤 DB에 접속하여 잘 적용이 됐는지 확인해주었습니다.
쿼리 속도 확인
쿼리 속도를 확인하기 위해 부하테스트를 실시하고 로그가 담겨있는 테이블을 조회했습니다. 로그는 ap 서버에서 보낸 쿼리 뿐만 아니라 RDS에서 관리용으로 보낸 쿼리도 섞여있으므로, user_host를 통해 필터링해주었습니다.
select * from mysql.slow_log
where user_host = 'admin[admin] @ [172.31.44.36]'
order by query_time desc;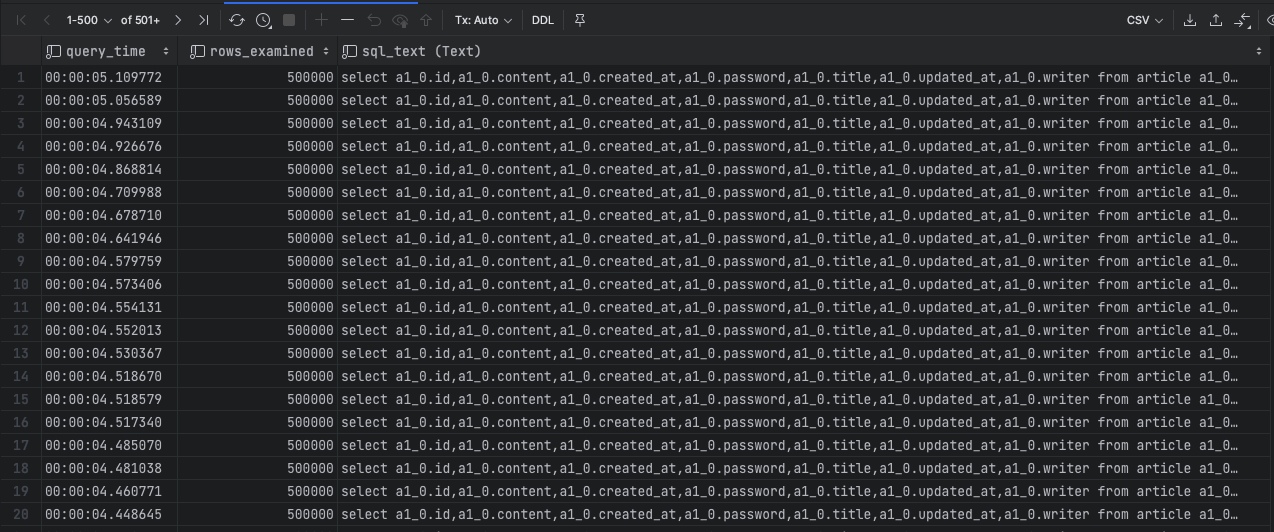
쿼리 수행시간으로 내림차순으로 정렬한 결과 대부분의 쿼리는 5초 이내에 수행됨을 확인할 수 있었습니다. 아래에서는 AP 서버에서 전달되는 쿼리를 하나하나 분석한 결과를 작성하겠습니다.
쿼리 분석
게시판 페이지 조회시 발생하는 쿼리
select a1_0.id,a1_0.content,a1_0.created_at,a1_0.password,a1_0.title,a1_0.updated_at,a1_0.writer
from article a1_0
order by a1_0.id
desc limit ?,?이 쿼리는 All Article Page와 Recent Article Page에서 사용되는 쿼리입니다. Article을 최신순 (id order by desc)으로 정렬하고 페이징을 하기 위해 limit이 사용됐습니다. 쿼리 로그를 통해 해당 쿼리의 수행시간을 살펴보았습니다.
왜 정렬을 ID 기준으로 했나요?
❓왜 정렬을 ID를 기준으로 했나요? 현재 시스템에서는 ID를 기준으로 역순 정렬을 하면 최신순 정렬과 동일한 효과를 얻을 수 있습니다. created_at 을 통해 정렬한 것과 결과의 차이는 존재하지 않을 것 입니다. 하지만 본질적으로 ID는 생성일시와는 관련이 없어, 이후 상황에 따라서 ID를 통한 정렬이 최신순을 보장하지 않게될지도 모릅니다. 억지 예를 들자면 만약 외부의 글 데이터들을 기존의 테이블에 추가해야할 경우가 발생한다 했을 때, 해당 글 들은 auto_increment를 통해 높은 ID값을 배정받을 것이고 이는 더 이상 ID를 통해 최신순 정렬을 하지 못하는 상황을 만들어 냅니다. 하지만 이런 일이 절대 발생하지 않을 것으로 예상된다면, ID를 통해 정렬하는 것은 꽤나 합리적으로 보입니다. 1. 별도의 Index를 추가로 설정하지 않아도 됩니다. created_at을 통해 정렬을 수행하는 쿼리를 효과적으로 사용하기 위해서는 created_at에 인덱스를 걸어야 할 것입니다. 이는 추가적인 디스크 공간을 사용하게 됩니다. 2. ID 인덱스를 통해 데이터를 가져오는 경우 InnoDB에서의 클러스터링 테이블 효과로 일반 인덱스보를 사용하는 것보다 더 빠르게 수행될 수 있습니다. 3. 하지만 일반적인 게시판에서 생성 일시를 통해 값을 찾거나 생성 일시의 범위를 통해 글을 검색하는 로직은 거의 등장하지 않는 것 같습니다. 인덱스를 통해 얻을 수 있는 이점을 모두 누릴 수 없습니다. 4. full-text 인덱스를 사용한 쿼리의 경우, created_at의 인덱스는 쓸모없어집니다. 일반 인덱스와 full-text 인덱스는 multi-column index를 구성할 수 없습니다. 따라서 full-text 인덱스를 사용하는 경우 정렬은 별도로 수행됩니다. 그럼에도 불구하고 정렬은 created_at을 통해 수행하는 것이 좋다는 생각이 들긴 합니다. created_at을 통해 정렬을 할 때에 쿼리와 데이터간의 일관성이 생기고 이후 테이블의 변화에 대처하기 유리할 것이라 생각합니다. 이 예제는 최대한 간단하게 진행하기 위해 ID를 통해 정렬하기로 합니다.


쿼리의 수행시간은 0.001 초부터 5초까지 분포가 다양했습니다. 기록되어있는 480개 가량의 쿼리 중 430개는 1초 이내에 수행되었고 나머지 50개만 1초 이상의 시간이 걸렸습니다.
주요하게 볼 점은 쿼리들 간에 rows_examined 값이 크게 차이가 난다는 점입니다.
rows_examined는 쿼리 실행 도중에 실제로 검사된 레코드(행)의 수를 의미합니다. 이는 필터링 전에 검사된 모든 행을 포함합니다.
rows_examined가 높지만 반환된 결과 행 수(rows_sent)가 적은 경우, 이는 쿼리가 많은 양의 데이터를 스캔하지만 실제로는 적은 양의 데이터만 필요로 한다는 것을 나타냅니다. 이런 경우 인덱스의 추가나 쿼리의 수정이 필요할 수 있습니다.
- 반면,
rows_examined와 반환된 결과 행 수가 거의 비슷한 경우, 쿼리가 필요한 데이터만 효율적으로 스캔하고 있다는 것을 의미합니다.
이러한 상황이 발생한 이유를 알아보기 위해 실행계획을 확인해 보았습니다.

이 쿼리는 내부적으로 Backward Index Scan이라는 방식에 의해 동작합니다. Backward Index Scan은 말 그대로 인덱스를 역순으로 조사한다는 의미입니다. 페이징을 위해 N개를 거른 뒤의 10개의 데이터를 가져와야 하므로, id를 기준으로 역순으로 스캔하여 원하는 데이터를 가져오게 됩니다.
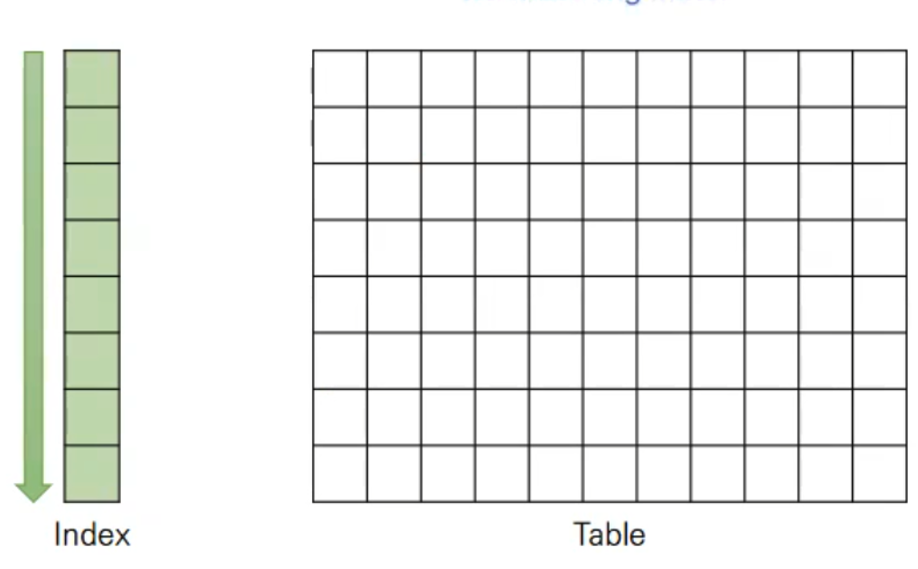
이 과정에서 최신 페이지는 거르게 될 인덱스의 수가 적으므로 금방 데이터를 반환하는 반면에, 과거 페이지일수록 거르게 될 인덱스가 많아 전체를 스캔하게 됩니다.
한편 대부분의 요청은 최신 페이지에 집중되어있으므로 평균 수행시간은 0.44초 정도로 나타났습니다. 따라서 이 쿼리의 튜닝은 뒤로 미뤄도 좋을 것으로 판단하고 넘어갔습니다.

Article count 쿼리
select count(a1_0.id) from article a1_0;페이징에서 사용되는 article의 크기를 가져오는 쿼리입니다. 대부분 0.3초 정도로 수행되므로 준수해보입니다.

개별 글 조회 쿼리
select a1_0.id,c1_0.article_id,c1_0.id,c1_0.content,c1_0.created_at,c1_0.password,c1_0.updated_at,c1_0.writer,a1_0.content,a1_0.created_at,a1_0.password,a1_0.title,a1_0.updated_at,a1_0.writer
from article a1_0
left join comment c1_0
on a1_0.id=c1_0.article_id
where a1_0.id=?개별 글을 보여주기 위해 발생하는 쿼리로, article의 정보와 함께 연관이 있는 comment를 join하여 가져오고 있습니다. 이 경우 Join Target인 comment.id는 인덱싱이 되어있어서 데이터를 금방 가져올 수 있었습니다.


게시판 글 검색 시 발생하는 쿼리
select a1_0.id,a1_0.content,a1_0.created_at,a1_0.password,a1_0.title,a1_0.updated_at,a1_0.writer
from article a1_0
where a1_0.title like ?
escape '\\'
order by a1_0.id desc limit ?,?Article의 title을 기준으로 필터링하여 그 일부를 페이징으로 가져오는 쿼리입니다.

title을 통해 필터링을 해야하기 때문에, 모든 열을 스캔해야하며 그 과정에서 테이블 스캔을 수행하기 때문에 5초 정도의 긴 시간이 걸렸습니다.

하지만 모든 쿼리가 5초의 시간이 걸린 것은 아니었으며, 일부 쿼리의 경우 0.004초만에 결과를 반환하기도 했습니다. 평균적으로는 3초의 시간이 걸렸습니다. 이러한 차이는 왜 발생한 것일까요?

일부 쿼리의 경우 조사된 열의 개수가 매우 적음을 확인했습니다. 이는 페이징(limit)이라는 특성에 기인한 것이었습니다.
수행시간이 오래걸리는 쿼리들은 ‘title50000’ 혹은 그 이상의 값을 가진 title을 검색하고 있습니다. Article의 개수는 50만개이고 이들은 각각 title1 부터 title500000까지의 이름을 갖고 있습니다. 따라서 ‘title50000’을 기준으로 검색은 다음과 같은 양상을 띄게 됩니다.
- title50000보다 낮은 경우 : 검색 결과는 최소 11개 이상임.
- ex) ’title40000’ 이 포함된 게시물 검색 : title40000, title400000, title400001, … ,title400009 (11개)
- ex) ‘title4000’ 이 포함된 게시물 : title4000, title4000X, title40000X (111개)
- title50000보다 높은 경우 : 검색 결과는 무조건 1개임
- ex) ‘title60000’이 포함된 게시물 : title60000 1개 (title600000은 존재하지 않음)
이 양상에 따라 스캔이 중지되는 지점이 달라집니다. 쿼리는 다음과 같이 동작합니다.
- ID를 기준으로 역순으로 스캔을 시작한다. (order by id desc)
- where 조건 (title)이 맞는지 체크한다. (where title like …)
- 결과를 10개 찾게 되면 스캔을 중지한다. (limit 0,10)
따라서 총 결과가 10개가 안되는 쿼리들은 테이블 전체를 스캔한 뒤 찾았던 결과만을 반환하게 되며, 총 결과가 10개 이상인 쿼리들은 10개를 찾게 되면 스캔을 중지하고 결과를 반환하게 됩니다.

위 쿼리는 ‘title49270’이 포함된 Article을 조사하는 쿼리였습니다. 따라서 역순으로 스캔하여 500,000번 부터 497,200까지 총 2801개의 row만 스캔하면 10개의 데이터를 찾을 수 있기 때문에 빠르게 반환할 수 있었던 것이었습니다.
이 문제를 해결하기 위해서는 모든 데이터를 스캔하면서 조건절을 검색하지 않게 title에 인덱스를 사용할 필요가 있어 보입니다. Title에 인덱스를 사용하면 Index Full Scan을 하지 않고 조건에 맞는 title만을 조사하여 결과 row들을 찾을 수 있을 것이라고 기대됩니다.
Article Search의 페이징을 위한 쿼리
select count(a1_0.id)
from article a1_0
where a1_0.title like ?
escape '\\'페이징에 필요한 결과를 제공하기 위해 title로 제공된 문자열을 담고 있는 article의 크기를 반환하는 쿼리입니다.

평균적으로 2.5초로 꽤 긴 시간이 걸렸습니다.
근데 ‘게시판 글 검색 시 발생하는 쿼리’에서 쿼리마다 수행 속도에 차이가 있었던 이유는 rows_examined에서 차이가 났기 때문입니다. 하지만 이 쿼리에서는 모두 rows_examined가 동일한데 실행시간에 차이가 많이 나는 쿼리들이 존재했습니다. 얘네들이 왜 빨리 수행됐는지는 잘 모르겠습니다.

이 쿼리들도 title을 인덱싱하여 스캔 범위를 좁히고 빠르게 수행될 수 있게 만들 수 있을 것이라 생각됩니다.
다음 글에서는 분석된 결과를 토대로 인덱스를 생성하여 쿼리 수행시간을 단축시켜보고, 그 결과를 확인해보겠습니다.
Uploaded by N2T