
개요
단일 프로세스 프로그래밍uniprogramming 시스템에서 메인 메모리는 OS의 kernel이 차지하고 있는 영역과 User Program이 차지하고 있는 영역으로 나뉘어 있다. Multiprogramming 시스템에서 User Program이 차지하고 있는 영역은 더 세분화되어 프로세스별로 나뉘어있다. 메인 메모리를 세부적으로 나누는 것은 프로세스의 생성, 삭제, swapping에 따라 OS로부터 동적으로 이루어지는데, 이를 Memory Management라고 한다.
Memory Management Requirements
Memory Management는 다음과 같은 요구사항을 만족시켜야 한다.
Relocation
다중 프로세스 프로그래밍Multiprogramming 시스템에서 프로그램의 실행 중 메모리 주소가 어디가 될지 사전에 알 수 있는 방법은 없다. CPU utilization을 위해 active process가 swap-in, swap-out하는 경우도 발생할텐데, 이때 swap-out 된 process가 다음번 메모리 적재에 기존에 할당됐던 주소공간에 다시 할당되는 것은 (주석: 다른 프로세스가 할당돼있을 수도 있기 때문에) 제한될지도 모른다. 이런 경우 Relocation을 통해 메모리의 다른 공간에 프로세스가 할당되어야 한다.
일단 단순성을 위해, 프로세스가 메모리의 연속적인contiguous 공간에 할당된다고 가정하자. OS는 PCB를 통해 execution stack이나 entry point to begin execution을 알고 있기 때문에 (주석: PCB에는 block 되기 직전의 cpu register 등을 비롯한 정보들이 저장되어있다), 이 주소들은 손에 넣기 쉽다. 그러나 프로세서는 PCB의 정보 뿐만 아니라 이후 프로그램이 다루는 내부 memory reference도 다뤄야 한다. 이것들을 다루기 위해 프로세서와 OS는 소스코드에 존재하는 memory references들을 현재 프로세스가 할당되어있는 메모리 공간의 주소로 변환translate 해줘야 한다.
Protection
각각의 프로세스들은 다른 프로세스의 의도되지 않은 간섭unintended interfere 으로부터 보호받아야 한다. 프로세스들은 다른 프로세스에 대해 허가되지않은 Read/Write instruction을 수행하면 안된다. Relocation Requirement 를 충족하는 것은 매번 다른 주소를 배정받기 때문에 Protection Requirement를 만족하지 못하는 위험을 증가시킬 수 있다. 매번 다른 주소를 배정받기 때문에 절대적인 주소를 통해 protection을 보장할 수 없다. 게다가 대부분의 프로그램은 접근할 메모리 주소를 동적으로 계산하기 때문에 이러한 위험도는 더 증가한다. 이러한 이유로 프로세스의 모든 메모리 접근은 런타임에 체크되어야 한다. 프로세서는 다른 프로세스의 메모리 주소에 접근하게 되는 것을 수행이 일어나는 순간에 막을 필요가 있다.
이러한 Protection은 OS(Software)가 아닌 processor(hardware) 로부터 수행되어야 한다. OS가 프로그램이 수행할 모든 memory reference 를 예상할 수 없기 때문이고, 예상한다 하더라도 프로그램 준비에 대한 오버헤드가 크게 발생할 것이다. 이를 해결하기 위해서는 모든 메모리 요청을 요청이 되는 순간 검증해야하고, 결국 하드웨어가 그 검증 능력을 갖고 있어야 한다.
Sharing
Memory Protection이 이뤄짐과 동시에 일부 경우Memory Sharing도 할 수 있어야 한다. 많은 프로세스에서 공유되는 프로그램과, 동기화 및 협력하는 프로세스에서 그렇다. 많은 프로그램에서 공유되는 프로그램 그것을 사용하는 프로세스들로부터 각각의 copy본을 갖고있을 필요는 없다. 또한 협력하는 프로세스는 서로의 메모리를 참조해야할 필요가 있다. 따라서 Memory Management 시스템은 기초적인 Memory Protection과 타협하여 서로의 프로세스에 접근하게 하는 매커니즘을 제공해야한다.
Logical Organization
메인 메모리와 Secondary Memory는 physical 한 레벨에서 linear, one-dimensional 하게 구성되어있다. 이러한 구조는 실제 하드웨어의 모습과 닮아있지만, User Program의 모습과는 다르다. User Program은 여러 수정가능한 모듈과 수정불가능한 모듈로 이루어져있다. 만약 OS 와 hardware가 이것들을 효과적으로 다룬다면, 다음과 같은 이점을 가져올 수 있다.
- 모듈이 런타임에 독립적으로 write되고 compile 될 수 있다.
- 적은 오버헤드로 각각의 다른 모듈에게 서로 다른 정도의 protection 정도를 부여할 수 있다.
- 모듈이 서로다른 프로세스에 의해 공유되게 할 수 있다. 이것은 우리가 프로그래밍할때의 관점과 맞아 떨어진다.(주석: 프로그래밍할때 공유되는 모듈은 하나만 작성하고, 이를 사용하는 측에서 참조하여 사용하게 한다)
이러한 요구사항을 만족시킬 수 있는 기술은 Segmentation이다.
Physical Organization
Main memory - Secondary Memory Scheme 에서, 두 메모리의 데이터 flow는 중요한 이슈이다. 이러한 것을 개발자가 관리하게 할 수 있지만, 이것은 두가지 이유에서 비실용적이고 권장될만하지 않다.
- 프로그램과 데이터를 위한 메인 메모리 공간이 충분하지 않다. 이것을 개발자가 관리하는 경우 다양한 모듈이 메모리에 같은 영역에 중복되는 overlaying이라는 문제에 맞닦뜨리게 되고, 이 경우 Main memory는 Secondary memory와 in and out을 진행해야한다. 컴파일러 도구의 도움을 받는다 해도, 이것은 개발자의 생산성을 떨어트리게 된다.
- Multiprogramming 환경에서, 프로그래머가 개발하는 순간에는 얼마나의 공간이, 어디의 공간이 사용가능할지 알 수 없다.
따라서 두 계층의 메모리간의 데이터 전송은 OS의 책임으로 두는것이 효율적일 것이다. 이 부분은 Memory Management의 가장 핵심적인 부분이다.
Memory Partitioning
Memory Management의 가장 중요한 기능 중 하나는 프로그램을 프로세서가 실행할 수 있도록 메인메모리에 옮기는 것이다. Multiprogramming 환경에서, 이 방식은 Virtual Memory라는 훌륭한 방식과 관련되어있다. Virtual Memory는 Paging과 Segmentation이라는 기술을 근간으로 한다. 이 기술을 살펴보기 전에, Virtual Memory와 관련없는 더 간단한 기술인 Partitioning 에 대해 알아볼 것이다.
Fixed Partitioning
Memory Management를 통해, OS 가 main memory 의 고정된 부분을 차지하고 있을 것이고, 나머지 부분은 User Processes가 사용할 것이라는 것을 가정한다. 이 나머지 부분을 관리하는 가장 간단한 방식은 이것들을 고정된 크기의 지역들로 나누는 것이다.
Partition Sizes

Partition 을 나누는 방법 중 하나는 모든 것을 동일한 크기로 나누는 것이다. 이 경우, 프로세스의 크기가 partition의 크기보다 작거나 같은 경우에만 메모리에 적재될 수 있다. 만약 partition이 다 차있고, Ready 나 Running 상태의 프로세스가 없다면(주석 : 모든 프로세스가 I/O operation 등의 이유로 block된 상태를 의미한다. Cpu가 열심히 context switch를 하며 돌면 이 상태가 된다. 이 상태에서는 cpu가 수행할 프로세스가 없기 때문에 유휴상태가 발생하여 utilization이 떨어지므로, Suspend/Ready 상태에 있는 프로세스를 Ready 상태로 만들어 cpu를 점유할 수 있게 만들어야한다. 이 표현은 아래에서도 반복된다.), OS는 partition을 차지하는 프로세스 중 하나를 swap out 할 것이고, 다른 프로세스를 가져와 processor 가 동작하게 할 것이다.
이러한 구조에서는 두가지 문제점이 있다.
- 프로그램이 너무 커서 파티션에 안들어갈 수 있다. 이 경우 개발자가 overlaying을 사용하여 언제든 partition의 사이즈에 맞는 사이즈를 유지하도록 프로그램을 설계해야한다.
- 메인메모리의 효율이 극도로 떨어진다. 굉장히 작은 프로그램도 하나의 partition 전체를 차지한다. 이러한 현상, 즉 파티션의 프로세스가 파티션보다 작아 내부에 낭비되는 공간이 있는 현상을 내부 파편화internal fragmentation 라고 한다.
이러한 문제들은 Unequal-size partitions 를 통해 줄어들 수 있지만, 완전히 해결되지는 못한다.
Placement Algorithm
Equal-size Partitioning 에서 프로세스의 배치는 중요하지 않다. 공간이 남아있기만 한다면 어디 들어가든 똑같기 때문이다.
만약 모든 파티션이 다 차있고 그 프로세스 중 running or ready 상태인 것이 없다면, 새로운 프로세스가 들어갈 공간을 내주기 위해 swap-out 해야한다. swap-out 할 프로세스를 결정하는 것을 Scheduling Decision이라고 하는데, 이는 파트 4에서 다룰 것이다.

Unequal-size Partition에서는 프로세스를 할당하는데에 두가지 방식이 있다. 첫번째 경우는 프로세스가 들어갈 수 있는 가장 작은 파티션에 할당하는 것이다. 이를 위해서는 각각의 파티션마다 queue가 존재해야한다. 이 방식의 장점은 프로세스가 항상 internal fragmentation을 최소화하는 공간에 할당된다는 것이다.
이것이 각각의 파티션 기준으로는 가장 효율적인 방식인것처럼 보여도, 전체 시스템으로 봤을 때는 그렇지 않다. 예를들어 12M~16M의 크기를 갖는 프로세스가 들어올 수 있수 있는 파티션이 어떤 시점에 비어있다고 하자. 이 공간은 12M보다 더 작은 프로세스를 위해 사용될 수도 있음에도 불구하고 유휴상태로 기다리게 된다.
이러한 문제를 해결하기 위한 방법은 하나의 큐에서 모든 프로세스를 다루는 것이다. 프로세스가 할당될 차례가 되면 그것이 들어갈 수 있는 파티션 중 가장 작은 파티션이 선택된다. 이 우선순위는 파티션을 차지하는 비율이 가장 작은 (주석: internal fragmentation이 가장 심한) 프로세스를 쫓아내는 방식으로 설정 될 수도 있고, 기타 다른 요소를 기준으로 할 수도 있다.
Unequal-size Partitioning은 fixed-partitioning 보다 높은 수준의 유연도를 제공한다. 이것은 다른 방식보다 쉽기도 하고, 구현이 간단하여 OS의 오버헤드도 적은 편이다. 하지만, 다음과 같은 단점이 존재한다.
- 시스템 생성시 지정된 파티션 수에 따라 active한 프로세스의 수가 제한된다. 예를들어 전체 메모리에 1000개의 아주 작은 영역을 차지하는 active 한 프로세스가 들어갈 수 있는 공간이 충분할지라도, partitioning 이 되어있어 그 개수만큼만 active 프로세스가 배치될 수 있다.
- Partition이 시스템 생성 시간에 미리 설정되기 때문에, 소규모 작업인 경우 partition의 효용성이 떨어진다. (주석: 오직 10개의 프로세스만이 필요한 키오스크 컴퓨터가 있다고 할 때 100개의 파티션을 만들 필요는 없다)
이러한 이유로 Fixed Partitioning은 오늘날 거의 사용되지 않는다. 과거 IBM의 mainframe OS인 OS/MFT에서는 사용됐다고 한다.
Dynamic Partitioning
Fixed Partitioning 의 단점을 극복하기 위해, Dynamic Partitioning이 고안되었다.
Dynamic Partitioning에서, 각각의 파티션은 length 와 number를 갖는다. 프로세스가 메인메모리에 할당될 때, 정확히 그 프로세스가 필요한 만큼의 메모리 영역만 할당받는다.
아래 예제의 (b), (c), (d) 에서 각각의 프로세스에 필요한 영역을 순차적으로 할당받는다. 이때 맨 아래에는 ‘hole’이 남게 되고, hole은 네 번째 프로세스가 들어가기에는 너무 작다. 이 지점에서, 만약 모든 프로세스가 ready 상태가 아니라면, OS는 프로세스 4가 들어가기 충분한 메모리 공간을 갖고있는 프로세스 2를 Swap-out 해버리고 (주석: swap-out의 대상이 되는 프로세스는 scheduling decision에 의해 변경될 수 있다) 그곳에 프로세스 4를 할당한다. 프로세스 4는 프로세스 2보다 작기 때문에, 이곳에 또다른 hole이 생긴다. 이후 모든 프로세스가 다시 ready 상태가 아님과 동시에 swap-out 됐던 프로세스 2가 suspend/ready 상태라면, 프로세스 1을 swap-out 시키고 그곳에 프로세스 2를 할당한다.

이 예제가 보여주듯이, 이러한 방식은 메모리 공간에 많은 hole을 만들게 된다. 시간이 지나면 지날수록 메모리 공간은 점점 파편화fragmented되고 메모리 효율성이 떨어질 것이다. 이러한 현상을 외부파편화external fragmentation 라고 한다. 외부 파편화는 유휴 메모리 공간이 충분하더라도 그것이 파편화되어있어 새로운 프로세스가 들어가기 어려운 상황을 만든다.
External fragmentation을 해결하기 위한 방법으로 압축compaction 이 있다. Compaction이란 OS가 일정한 주기로 프로세스들을 contiguous 할 수 있게 옮겨서, 유휴 공간이 하나의 블록으로 유지될 수 있게 하는 방법이다. 위 예제의 경우 Compaction을 통해 총 16MB의 메모리 블록을 확보할 수 있고, 이를 통해 기존에는 할당되기 위해서 swap-out 이 필요했던 16MB짜리 프로세스도 swapping 없이 메모리에 할당될 수 있다.
하지만 compaction은 시간이 걸리는 일이고 cpu time을 낭비하게 된다. 또한 compaction은 dynamic relocation을 필요로 한다. 메모리의 공간을 옮기는 것은 dynamic relocation이 없다면 기존의 memory reference가 망가지게 만들 것이다.
Placement Algorithm
Compaction은 상당한 시간이 걸리는 작업이기에, OS는 메모리에 프로세스를 할당하는 의사결정을 더욱 주의깊게 해야할 것이다. 만약 프로세스가 들어갈 수 있는 여러개의 hole들이 존재한다면, OS는 어떤 hole에 할당할지 결정해야한다.
Best-fit이란 프로세스의 크기와 가장 비슷한 크기의 hole을 선택하는 전략이다. First-fit은 메모리를 가장 위에서부터 탐색하기 시작하여 이용가능한 첫번째 hole을 선택하는 전략이다. Next-fit 은 최근에 할당되었던 주소부터 탐색하기 시작하여 이용가능한 첫번째 hole을 선택하는 전략이다.

Figure 7.5는 각각의 전략에 의해서 선택된 hole들의 위치를 보여준다. First-fit은 6MB의 파편을, Best-fit 은 2M의 파편을, Next-fit은 20M의 파편을 만들었다.
사실 이 결과는 어떤 기존의 프로세스가 swap-out되느냐에 달려있다. (주석: 하지만 이에 대한 general한 연구결과가 있다. First-fit는 구현이 쉬울 뿐만 아니라 일반적으로 가장 최적이면서 빠르다. Next-fit 은 first-fit 보다 살짝 떨어지는 결과를 낳는 경향이 있다. Memory의 뒤쪽에 있는 free hole은 일반적으로 메모리에서 가장 큰 유휴공간인데, next-fit은 이공간을 더 자주 차지하여 더 작은 파편을 만들어내기 때문이다. 따라서 next-fit 은 더 잦은 compaction을 요구한다. 반면 first-fit은 메모리 전반부에 작은 파편을 많이 만들어 내어, 이후의 first-fit 을 찾는 작업들에 있어서 무의미한 탐색을 증가시킬수 있다. (원본: On the other hand, the first-fit algorithm may litter the front end with small free partitions that need to be searched over on each subsequent first-fit pass)
사실 best-fit은 그 이름과 맞지 않게, 가장 안좋은 성능을 보인다. best-fit은 가장 작은 크기의 파편을 만드는 것을 보장한다. 비록 각각의 메모리 할당 요청을 통해 가장 작은 크기의 파편을 만든다고 하여도, 결과적으로 메인 메모리는 메모리 할당 요청을 충족시킬 수 없는 크기가 너무 작은 블록들로 빠르게 채워지게 된다. 그러므로, best-fit은 다른 방식보다 더 잦은 compaction을 요구한다.
Replacement Algorithm
멀티프로그래밍 환경에서 dynamic partitioning을 사용하더라도, 추가적인 프로세스 할당을 위해 swap-out 해야하는 상황은 온다. Processor 효율을 늘리기 위해서 메모리의 block되어있는 프로세스를 swap-out 하고, Suspend/Ready 에 있는 프로세스를 할당해야한다. 이 주제는 Virtual Memory System을 할 때 더 상세히 다루기 때문에, 그때 가서 논의하기로 한다.
Buddy System
Fixed Partitioning 과 Dynamic Partitioning 은 모두 단점을 갖고 있다. Fixed Partitioning은 active 상태의 프로세스 수가 제한되며, partition size와 process size가 잘 매칭되지 않을 때 메모리를 비효율적으로 사용하게 된다. Dynamic Partitioning은 유지하기 더욱 복잡하고, compaction의 오버헤드를 갖는다. 이에대한 흥미로운 타협안은 Buddy System이다.
Buddy System에서 메모리 블록은 개의 words로 이용가능하다.
를 만족해야하고, 각각은 다음의 조건을 만족해야한다.
= 할당된 가장 작은 사이즈의 블럭
= 할당된 가장 큰 사이즈의 블럭; 일반적으로 이것은 전체 메모리에서 할당에 사용할 수 있는 크기
가장 먼저, 메인 메모리의 할당할 수 있는 전체 크기를 의 크기를 갖는 하나의 블록으로 여긴다.
만약 메모리 할당 크기 s가 라면, 해당 블록에 프로세스를 할당한다. 만약 그렇지 않다면(주석: s가 보다 더 작다면), 의 블록을 두개의 동일한 사이즈를 갖는 Buddy로 분할한다. 분할된 블록의 사이즈는 각각 일 것이다. 만약 s가 이라면, 둘 중 하나에 할당하고, 아니라면 또 분할한다. 이 과정은 s가 할당될 수 있는 적당한 크기의 블록이 생길 때 까지 반복된다.
언제든지 Buddy System에서는 사이즈가 인 hole들을 유지하게 된다. 의 사이즈를 갖는 hole은 두개의 buddy로 쪼개지므로써 사라질 수도 있다. 만약 한 쌍의 buddy가 replacement algorithm에 의해 모두 unallocated된 상태라면, 그들은 합쳐지고 i+1의 사이즈를 갖는 블록으로 바뀐다. 이러한 작업은 recursive 하게 이뤄질 수 있다.
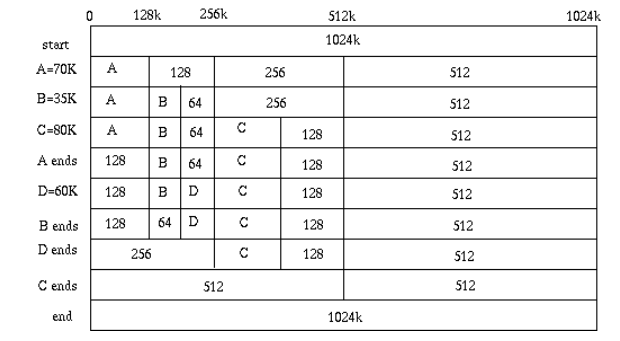
위 그림은 Buddy System의 예제이다. 맨 처음에는 하나의 큰 블록이 존재하고, 70K의 요청이 들어오고 나서는 여러 buddy들로 쪼개지며 적절한 공간에 프로세스 A가 할당된다. B가 메모리 할당이 해제되는 상황에서는 128의 크기를 갖는 buddy가 unallocated된 상태이기 때문에 256의 크기를 갖는 하나의 블록으로 합쳐진다.
버디 시스템은 fixed, dynamic partitioning의 단점을 극복할 수 있는 합리적인 타협안이지만, 현대의 OS에서는 virtual memory 와 paging에 근간한 기술들이 더 많이 사용된다. 하지만 buddy system은 병렬 프로그래밍에서 프로세스 할당과 해제에 있어 매우 효율적인 수단이다. 수정된 버전의 buddy system은 UNIX 커널 메모리 할당 시스템에서 사용되고 있다.
Relocation
Partitioning에 대한 단점을 고려하기 전에, 우리는 프로세스의 placement에 대한 부분을 확실히하고 넘어가야한다. 각각의 partition마다 큐를 관리하는 Fixed Unequal Partitioning 방식에서, 프로세스들은 항상 같은 파티션에 할당된다. 이 말은 즉슨, 새로운 프로세스가 로드 될때 swap-out되는 파티션에 swap-in이 발생한다는 것이다. 이러한 경우 simple reloacating loader 가 사용될 수 있다. simple reloacating loader는 가장 처음 loading 될 때, 소스코드의 모든 상대 주소를 절대 메모리 주소로 교체한다. (주석: 항상 같은 메모리 파티션에 할당되기 때문에 absolute memory address를 사용하여도 무방하다)
반면 Equal-size Partition과 하나의 큐를 사용하는 Unequal Partitioning 에서는 swap-out 과 swap-in 과정에서 다른 파티션에 할당될 수 있다. 게다가 compaction이 사용된다면, 메모리 공간이 shift된다. 따라서 절대적인 메모리 공간은 고정되지 않은 상태다. 이러한 문제를 해결하기 위해서 몇가지 종류의 address를 구분하는 것이 필요하다. Logical Address란 현재 할당된 공간과는 상관없는independent 메모리 참조를 의미한다; 이 경우 메모리 참조를 할때에 physical address로 변환하는 과정이 필요하다. Relative Address란 logical address의 특정한 예로, address가 어떠한 포인트, 주로 프로세서의 레지스터를 기준으로 하여 상대적인 값으로 표현되는 주소이다. Physical Address란 절대적인 메인 메모리의 주소이다.
Relative address를 사용하는 프로그램은 dynamic run-time loading을 통해 로드된다. 일반적으로, 모든 메모리 참조의 로딩과정은 프로그램의 원본origin 과 관련이 있다(원본: All of the memory references in the loaded process are relative to the origin of the program). 하드웨어 매커니즘은 메모리 참조가 수행될 때 relative address를 physical main memory의 address로 변환해주는 과정을 필요로 한다.

위 그림은 address translation의 과정을 보여준다. 프로세스가 Running 상태가 된다면, Base Register 라고 불리는 special purpose register에 메모리의 시작 주소가 할당된다. “bounds register”라 불리는 레지스터에는 할당된 메모리의 끝 주소가 할당된다. 이 값들은 프로세스가 최초 로딩되거나 swap-in 될때 꼭 세팅되어야 한다.
수행 과정중에 relative address를 만난다면, 이 상대 주소들은 프로세서에 의해 두 단계에 의해서 조작된다. 먼저, base register 의 값이 상대주소에 더해져 absolute address를 만든다. 이후, 방금 만들어진 absolute address를 bounds register 와 비교한다. 만약 주소가 경계 안에 있다면valid 명령어가 수행되로 것이고, 만약 그렇지 않다면 OS에 의해 interrupt가 걸리고 에러를 뱉어낼 것이다.
위 그림은 프로세스가 swap-in swap-out을 하여 메모리의 다른 곳에 할당된다 할지라도 문제가 없게 만든다. (원본: The scheme of Figure 7.8 allows program to be swapped in and out of memory during the course of execution) 또한 이것은 Memory Protection의 수단이 된다: 각각의 프로세스는 base register 와 bounds register를 통해 그들 자신의 프로세스에만 접근할 수 있으며isolated, 다른 프로세스에 원치 않는 접근을 하는것을 막아준다.
Paging
Fixed Partitioning 과 Dynamic Partitioning 은 각각 internal fragmentation 과 external fragmentation을 발생시킨다. 그러나, 메모리가 동일한 작은 사이즈의 청크chunks 로 나뉘어 있고, 프로세스 역시 청크와 같은 사이즈로 나뉘어있는 상황을 가정해보자. 이러한 경우 프로세스의 나눠진 조각인 page는 이용가능한 메모리의 조각인 frame에 할당될 수 있다. 이를 통해 external fragmentation을 없앨 수 있으며, internal fragmentation 은 오직 프로세스의 마지막 page에만 발생한다.(주석: 프로세스가 2.1MB이고 청크의 사이즈가 1MB 일 때, 두개의 페이지는 1MB를 꽉 채울 것이고, 마지막 페이지는 0.9MB의 internal fragmentation 을 발생시킨다)


위 그림은 page와 frame의 사용을 보여준다. 각각의 시점에 어떤 프레임에는 페이지가 할당되어있고, 어떤 프레임은 비어있다free. Free frame 에 대해서 OS는 리스트를 유지해야할 것이다. 위 그림에서는 프로세스 A, B, C 가 각각이 필요로하는 만큼의 프레임에 들어가 있다. 이후 프로세스 D가 들어가기 위해서는 충분한 공간이 없으므로, 프로세스 B를 swap out 한 뒤 D를 배치하였다.
위 상황에서, D에게는 할당될 충분한 연속적인 메모리 프레임이 없다. 하지만 이러한 제한은 운영체제가 D를 loading 하는데 문제가 되지 않는다. 왜냐하면 logical address의 개념을 도입하면 해결되기 때문이다! 이 상황에서 base register는 더 이상 필요가 없다. 대신, OS는 page table이라는 것을 각각의 프로세스마다 생성해서 관리한다. Page table은 각각의 프로세스의 페이지마다의 frame location을 저장하고 있다. 이러한 방식하에서, logical address는 page number와 offset 으로 구성되어있다. 기존에 논의됐던 것 처럼, logical - to physical translation은 프로세서(하드웨어)에 의해 진행된다. 그렇기 때문에 프로세서는 현재 점유하고 있는 프로세스의 page table에 대해 알고 접근할 수 있어야 한다. 프로세서는 logical address(page number 와 offset)을 토대로, page table을 사용하여 physical address (frame number , offset) 을 만들어 낸다.

위 그림은 page table을 보여준다. Page table은 프로세스의 페이지 당 하나의 entry를 갖고있어서, page number 에 의해 쉽게 인덱스로 접근할 수 있다. 각각의 page table entry는 메인메모리 프레임에 해당하는 location을 갖고있다. 추가로, OS는 하나의 free frame list를 관리해서 현재 메모리에 어떤 프레임이 사용되고 있고, 어떤 프레임이 비어있는지 확인할 수 있어야 한다.
이러한 paging은 fixed partitioning 과 비슷해보인다. Paging은 fixed partitioning 과 다르게 partition이 매우 작고, 그러므로, 프로세스가 여러 파티션을 점유하게 된다. 또한 점유된 파티션은 연속될 필요가 없다.
Paging 방식을 좀 더 편리하게 만들기 위하여, page size이자 frame size를 2의 제곱 승으로 한다. 이러한 방식을 통해 relative address를 page number와 offset으로 구성할 수 있다.

위 그림에서는 16-bit의 주소체계가 사용되며, page size는 1K(1,024 bytes)이다. Relative Address 1502는 이진표현으로 0000010111011110 으로 표현되는데, 이것은 1K()의 page size를 갖는 경우 page offset을 위해 10개의 bit가 사용되고, 나머지 6개의 bit는 page number를 지정하는데 사용될 수 있다. 그러므로 하나의 프로그램은 총 개의 페이지를 가질 수 있게 된다. Relative address 1502(0000010111011110)는 1의 page number와, 478의 offset 과 상응한다.
2의 제곱수로 page size를 사용하는 방식의 결과는 두가지이다. 첫번째는 logical addressing 방식이 개발자, 어셈블러, 링커로부터 투명transparent 하다는 것이다.(원본: the logical addressing scheme is transparent to the programmer, the assembler, and the linker). 프로그램의 logical address는 relative address와 동일하게 작동한다. 둘째로, 런타임에서 하드웨어가 translation을 하는데에 유용하다. 하드웨어가 translation 하는 동작은 다음과 같이 작동한다.
n = page number, m = offset 이라고 할 때,
- logical address로부터 좌측의 n개의 bits를 가져온다. → page number
- page number를 토대로 process page table에서 frame number를 가져온다
- frame number는 m의 길이만큼 shift되고, 그곳에 m이 더해진다. 이러한 과정은 실질적으로 계산으로 동작하는 것이 아닌 붙이는appending 과정을 통해 동작한다.

위 그림에서는 page number 1 에 해당하는 frame number 6(000110) 과 offset 이 붙여져 physical memory address 0001100111011110 으로 translation 되는 과정을 확인할 수 있다.
요약하자면, paging에서 메인 메모리는 아주 작고 많은 동일한 크기의 조각들로 나뉜다. 프로세스들 역시 조각들의 사이즈로 나뉜다. 작은 프로세스는 적은 수의 페이지들로 구성되어있을 것이고, 큰 프로세스는 더 많은 페이지가 필요할 것이다. 프로세스가 메모리에 할당될 때, 모든 페이지는 비어있는 프레임에 로딩되고, 그 결과에 따라 page table이 초기화된다. 이러한 방법은 partitioning으로 인한 문제점을 대부분 해결한다.
Segmentation
User Program과 그것과 관련된 데이터들은 여러개의 segments로 나뉠 수 있다. segments의 길이는 max 값은 제한되어 있더라도, 각각의 segments들은 동일한 크기를 가질 필요는 없다. 마치 페이징처럼, segmentation을 사용할 때의 logical address는 segment number와 offset으로 나뉜다.
Segmentation은 각각의 조각의 크기가 동일하지 않기 때문에, dynamic partitioning이랑 비슷해 보인다. Dynamic partitioning과 다르게 segmentation은 프로세스가 한 개 이상의 partition을 사용할 수 있으며, 그 여러개의 파티션이 메모리 상에 연속적으로 존재하지 않아도 된다. Segmentation은 internal fragmentation에 의한 문제를 제거하지만, dynamic partitioning 과 마찬가지로 external fragmentation에 의한 문제를 해결할 수 없다. 물론, 프로세스가 잘게 쪼개져 저장되기 때문에 external fragmentation에 의한 피해는 dynamic partitioning보다 훨씬 적긴 하다.
Paging은 프로그래머의 입장에서 숨겨져서invisible OS에 의해 동작하지만, segmentation은 주로 프로그래머가 제어할 수 있으며 program 과 data를 구성하는데 편리함을 제공한다. 일반적으로, 프로그래머나 컴파일러가 프로그램과 데이터를 segments에 할당한다. 모듈 프로그래밍의 목적으로, 프로그램과 데이터는 더 작은 segments 로 분할 될 수 있다(원본: For purposes of modular programming, the program or data may be further broken down into multiple segments). Segmentation의 주요한 불편한 점은 프로그래머가 segment의 최대 크기를 알아야한다는 것이다.
Unequal Segmentation의 또 다른 결과는 paging과 같이 logical address와 physical address간의 간단한 관계성이 없다는 것이다. 마치 Paging처럼, segmentation 방식에서도 각각의 프로세스마다 segment table을 유지해야하며, 메인 메모리의 free blocks들을 관리하는 리스트도 유지해야한다. 각각의 segment table entry는 segment에 해당하는 메인메모리의 시작 주소에 대한 정보를 갖고 있어야한다. Table entry는 또한 segment의 길이에 대한 정보를 제공해서, memory reference가 segment 영역의 바깥을 가리키는 일이 없도록 해야한다. 프로세스가 Running State가 된다면, segment table의 주소가 memory management hardware 에 의해 special purpose register에 적재되어야한다.

왼쪽의 n비트가 segment number이고 우측의 m 비트가 offset 인 경우를 고려해보자. 위 예제에서는 n이 4이고, m이 12이다. offset 이 12이므로, 각각의 segment는 최대 =4096의 사이즈를 가질 수 있다. 다음은 address translation을 하는 과정을 설명한다.
- logical address의 좌측 n개의 비트에서 segment number를 추출한다.
- segment number 를 index로 하여 segment table에서 segment의 starting physical address를 찾는다.
- offset인 m과, segment 의 길이를 비교한다. 만약 m이 더 크다면, 이 요청을 invalid한 요청이다.
- 최종적으로 starting physical address와 offset을 합하여 요청하고자 하는 물리주소를 구한다.
요약하자면, segmentation에서 프로세스는 여러개의 서로다른 크기의 조각으로 나뉜다. 프로세스가 메모리에 실릴 때, 각각의 조각들은 메인 메모리의 서로다른 빈 공간에 할당되고, 그 결과를 segment table에 저장한다.
Summary
OS의 가장 중요하고 복잡한 일 중 하나는 메모리 관리이다. 메모리 관리는 메모리를 여러 active 한 프로세스들 사이에서 메모리를 할당하고 공유할 자원으로써 관리하는 것이다. Processor와 I/O facilities 를 효율적으로 사용하기 위해서는 많은 프로세스를 메모리에 유지하는 것이 필요하다.
메모리 관리를 위한 basic tools는 paging 과 segmentation이다. Paging을 통해, 각 프로세스는 작고 고정된 사이즈의 page로 나뉜다. Segmentation은 조각들을 서로 다른 크기로 나눈다. Segmentation과 Paging 을 하나의 메모리 관리 방식에서 혼합하여 사용하는 것 역시 가능하다.
Uploaded by N2T
